DeepDribble: Simulating Basketball with AI

Researchers from DeepMotion and CMU have taught virtual basketball players entirely physically simulated dribbling skills.
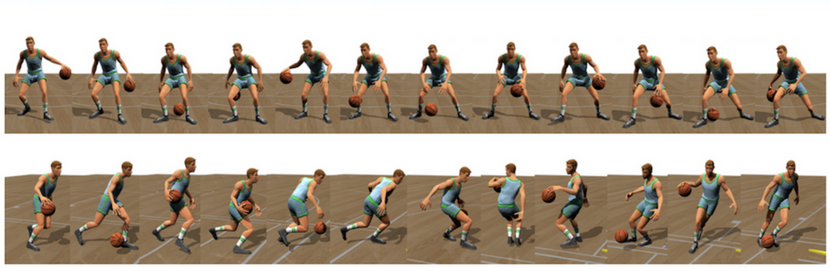
Top tier Basketball players exhibit powerful upper body dexterity, lower body agility, and mastery of ball coordination. When training physically simulated characters basketball skills, these competing talents must also be held in balance. While AAA game titles like EA’s NBA LIVE and NBA 2K have made drastic improvements to their graphics and character animation, basketball video games still rely heavily on canned animations. The industry is always looking for new methods for creating gripping, on-court action in a more personalized, interactive way.
In a recent paper by DeepMotion Chief Scientist, Libin Liu, and Carnegie Mellon University Professor, Jessica Hodgins, virtual agents are trained to simulate a range of complex ball handling skills in real time. This blog gives an overview of their work and results, which will be presented at SIGGRAPH 2018. We also cover how developers can leverage intelligent character simulation in their own content development.
The State of AI-Driven Motion Simulation
Reinforcement learning techniques have proven extremely successful in the creation of functional (albeit somewhat strange) locomotion in digital agents. Works like OpenAI’s Competitive Self Play or DeepMind’s Parkour Simulation employ state of the art algorithms to produce emergent motion in 3D humanoids. In the world of game animation, neural networks have been used in some enterprise titles like Grand Theft Auto V to craft procedural movements that, while undeniably lifelike, are relatively inflexible. Recent works from Liu and Hodgins, and other graphics papers like DeepMimic and DeepLoco, show promising results for lifelike, physics-based character animation. DeepDribble builds upon a variety of techniques to create performant character simulation for natural, simulated dribbling motions and transitions. The paper marks a breakthrough in character control systems that can handle physical objects during real-time simulation, while performing upper body movement and lower body locomotion.

Rigid Animation → Physical Simulation
In order to train the character physical skills, the researchers used biomechanical modeling to ascribe joints and torque to the character rig. This process physicalizes the standard character model, allowing it to balance and move by adjusting muscle torque. (Deep Motion’s Avatar Physics Engine uses a similar “articulated physics”). As shown in the DeepDribble paper, different joint sets can be trained separately for targeted skill development.
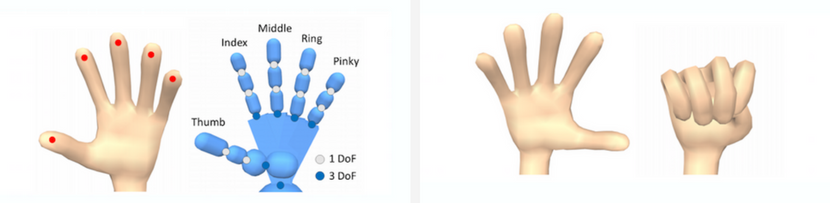
Hand Model [1]

Character Model [2]
The character is then taught locomotion control using a short clip of motion capture footage as reference data. This round of training teaches the controller to manipulate the character’s biomechanical model in order to perform a simulated version of the clip.
Initial training removes artifacts and glitching found in motion capture data—the preferred method for character animation in sports games—and transforms the canned animation into a real-time, procedural animation.

Basic Ball Handling: Trajectory Optimization and Linear Regression
A ball is not required in the initial training, rather it is reconstructed using trajectory optimization (estimating ball and hand movement given the arm position). From the reconstructed ball and hand movement, we can learn a linear regression model to handle various perturbations during the dribbling.

Such linear policies produce robust skills for simple ball handling tasks over the course multiple cycles.

While a linear policy (roughly: the method for an agent to determine what action to take based on its current state—in this case between fragments of the motion) approximates ball control, linear models are not sufficient for more advanced dribbling tasks, leading to eventual discoordination between the object and player.

Improving Arm Control in Advanced Tasks via a Nonlinear Policy
To produce persistent dribbling behaviors, researchers employed the DDPG (the Deep Deterministic Policy Gradient, Lillicrap et al. 2015) to improve arm and hand control.
The linear policy results are used to initialize the deep reinforcement learning training for efficiency. The resulting motion exhibits robust ball control, even when the player dribbles over long distances or encounters external perturbations.

A Multi-Skilled Character
Basketball at its peak is known for intricate ball handling, quick pivoting, and fake outs. A good player will fluidly transition between a variety of dribbling skills. In order to recreate this, the trained characters need to be able to transition between separately trained behaviors.

Liu and Hodgins use the same methods for training single skills to create a multi-skill control graph (which allows transition between motion fragments of two different skills). The training is done incrementally, behavior by behavior, to ensure integration occurs with proper transitions for each skill. The result is a player that can perform multiple ball handling skills in a variety of orders, changing course with seamless blending.
With a multi-skill control graph, end-users can direct the character to move across the court fluidly using various complex dribbling behaviors.

Creating Your Own Intelligent Character Simulations
Real-time, procedural character simulation adds nuance, unexpected details, and interactivity to gameplay—promising more dynamic gaming and immersive XR experiences. Liu and Hodgins’ paper shows the promise of Motion Intelligence (the ability to perform functional, physical behaviors in a natural way) for character animation. The same technology used to teach digital actors how to dribble can be applied to any physical movement. At DeepMotion we’ve used similar techniques to create DeepMotion Neuron: the first developer tool for completely procedural, physical character animation. The product is a Behavior-as-a-Service cloud platform for animators and developers, allowing users to upload their unique character files and transform them into interactive agents. Learn more and register for the Pre-launch here.
Left: Hand model used in this paper. The researchers used 1-DoF pin joint for proximal interphalangeal joints and distal interphalangeal joints, and 3-DoF ball and socket joint for metacarpophalangeal joints. The red dots on the fingertips are proxies used to calculate the distance between the ball and the hand. Right: The flat hand pose (left) and the fist pose (right) used for computing the target pose for hands. ↩︎
Character model. Left: skeleton and collision geometries. Right: rigged characters ↩︎